
Building High-Performance video classification service with Python
December 1, 2025
technical overview of implementing a scalable video classification service — documenting the architecture, processing requirements, and performance optimization strategies.
Overview
In this project, the goal was to design a high-throughput video classification service capable of processing 500,000 videos per day for a short-video platform similar to TikTok.
The classification task aimed to identify video genres across 31 predefined classes.
To meet this performance target within a 24-hour operational window, the system required a sustained processing rate of approximately:
This article outlines the engineering evolution of the system — from an initial monolithic, single-process prototype to a scalable, distributed architecture designed for high concurrency, fault tolerance, and efficient resource utilization. The transformation involved decomposing tightly coupled components into asynchronous, service-oriented modules, introducing task queuing and parallel processing pipelines.
1. Initial Implementation: The Baseline
The first implementation followed a monolithic, sequential workflow, where all processing steps were executed within a single process and thread. The API exposed a single endpoint that handled the entire pipeline end-to-end:
- Receive video URL — the API accepted a video URL from the client and downloaded the corresponding file to local storage.
- Extract audio features — the audio track was processed to compute relevant features which were then written to disk.
- Extract video features — using
cv2, visual frames were analyzed to derive relevant features, also stored on disk. - Run genre classification — both audio and video features were combined to infer the video’s genre across 31 predefined classes.
Each video required approximately 15 seconds of end-to-end processing.
Excessive disk I/O, sequential execution, and the absence of parallelism resulted in significant performance bottlenecks, limiting throughput and scalability.
2. Understanding the Data
Before optimizing, it was essential to understand what we were processing.
Using a dataset of 10,516 videos (sampled from object storage), we analyzed:
- Video size distribution (500 bins)
- Frame count distribution (500 bins)
- Duration distribution (5 bins)
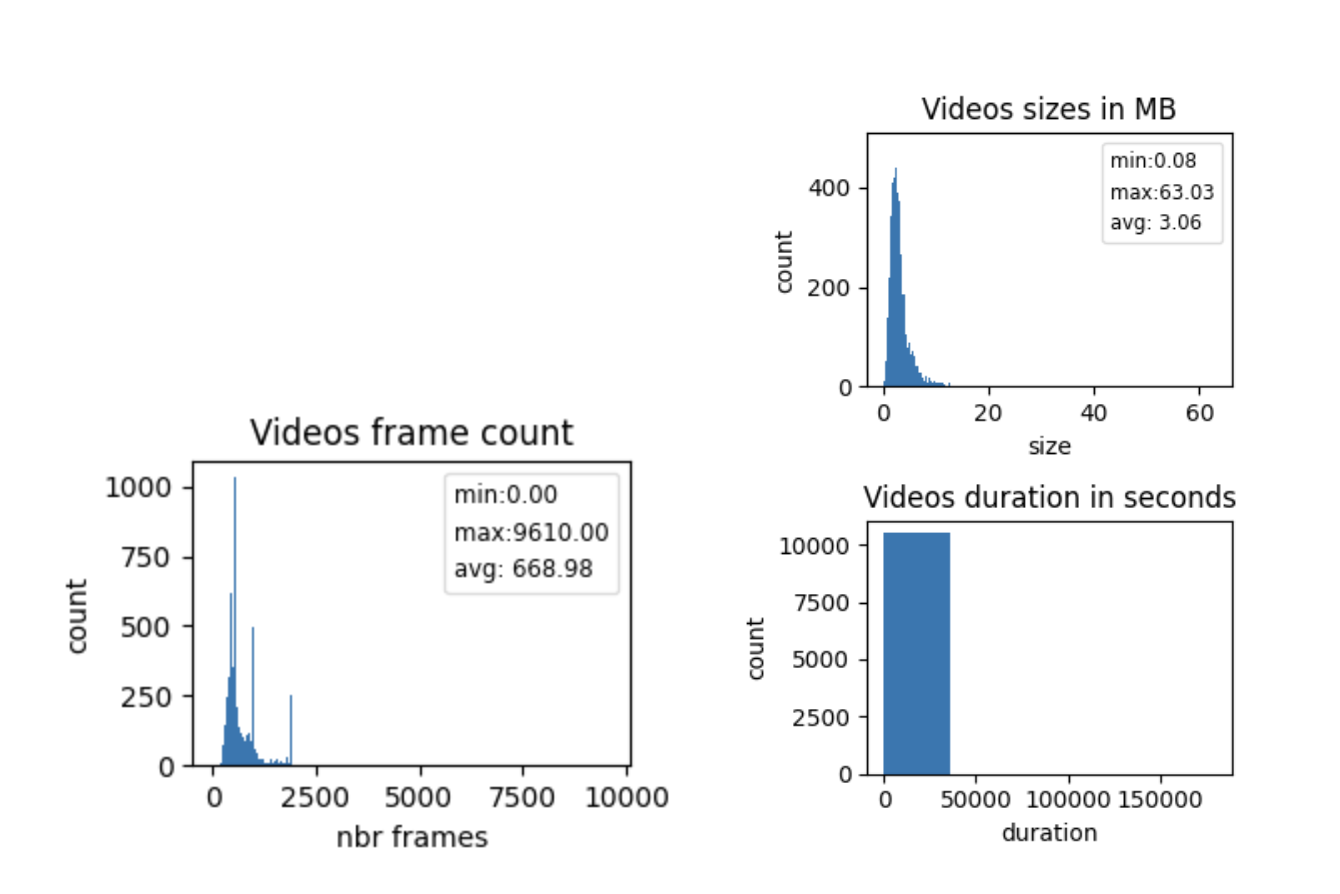
- Video size (MB): 50th percentile , 80th percentile , 95th percentile , max = 63.02.
- Frame count: , .
- Duration (s): most videos 30 s; exceptions: 30.303, 59.940, 60.0, 180000.0.
3. First Improvement
The system has been redesigned for parallelism and in-memory streaming and has been split into three independent REST services:
- Audio extraction
- Video extraction
- Genre classification
- The audio and video feature extractions are executed in parallel.
- No disk writes — data was passed via
BytesIO/StringIOstreams. - Processed on GPU V100 using 325 sample videos.
Each service operated without writing to disk and leveraged the PyAV library for efficient video I/O.
Performance Comparison
| Workflow | Min (s) | Avg (s) | Max (s) | Std Dev | Median | 80th | 95th |
|---|---|---|---|---|---|---|---|
| Sequential (cv2 + disk writes) | 5.04 | 11.08 | 25.82 | 3.93 | — | — | — |
| Parallel (cv2, no disk) | 2.84 | 6.19 | 26.80 | 2.65 | 5.58 | 7.30 | 10.41 |
| Parallel (PyAv, no disk) | 2.15 | 4.21 | 28.67 | 1.92 | 3.80 | 4.75 | 7.08 |
Result:
The optimized workflow improved by 2.63× on average and end-to-end time reduced to ~4 seconds per video:
- ~1s: download
- ~2s: audio + video feature extraction (in parallel)
- ~1s: classification
Limitation and key findings
- The API still waited for all sub-tasks to complete.
- Video downloading remains the major latency contributor.
- GPU offered limited improvement for single-video inference; batching is required to exploit full potential.
- Streaming data into REST APIs eliminates costly disk I/O.
- Compression provided no benefit to runtime or memory usage.
4. Second Improvement: Kafka-Powered Distributed Architecture
To improve scalability and throughput, we introduced Kafka as a messaging backbone.
- The API only queued video processing jobs.
- Audio and video extractors acted as Kafka consumers, producing feature vectors to a shared topic.
- The classifier service consumed these feature messages and produced final predictions.
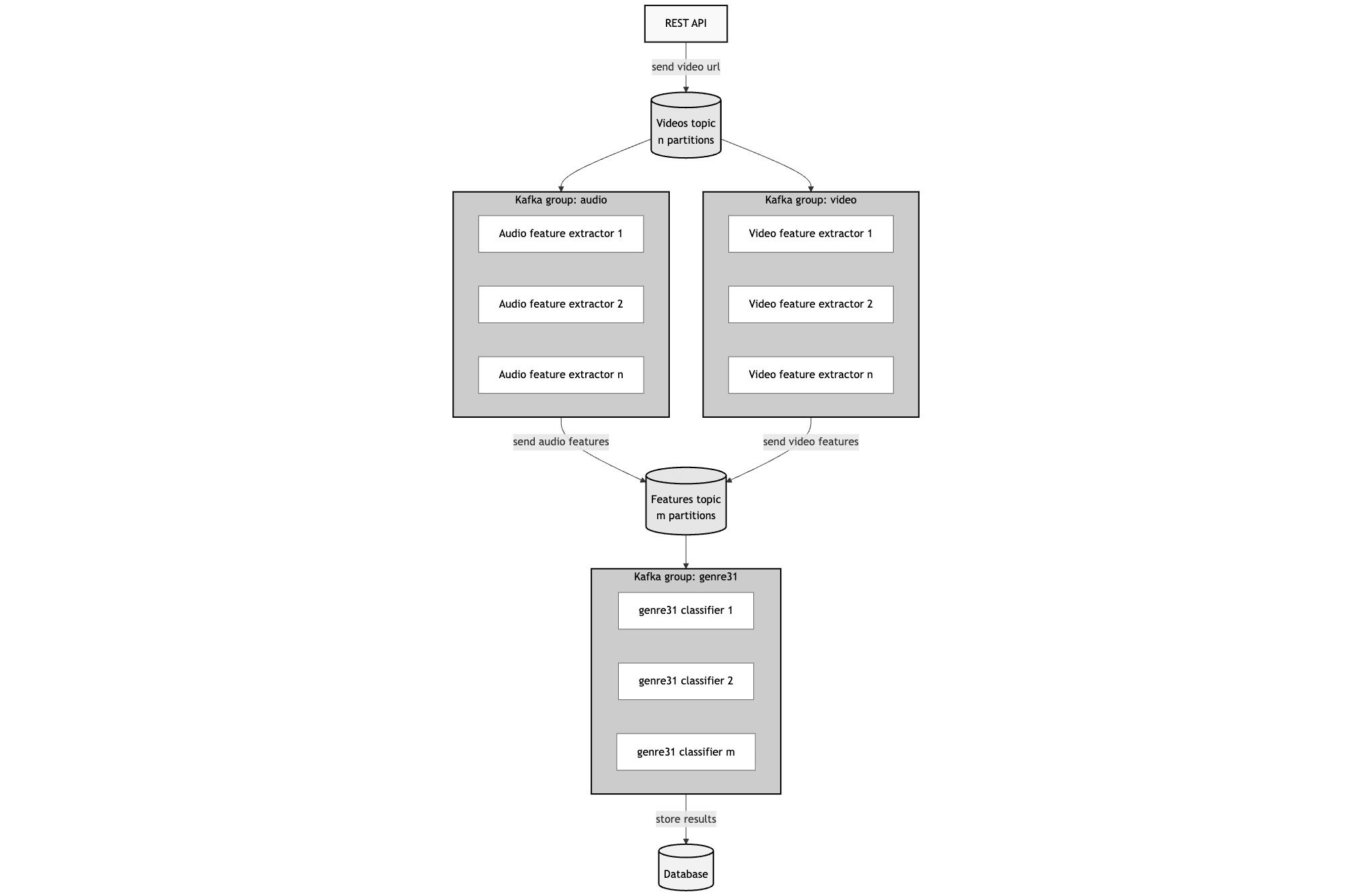
This decoupled architecture allowed:
- Asynchronous processing
- Natural load balancing
- Independent scaling of each component
Benchmark Results
- 1,800 requests total
- 60 RPS (requests per second) load via Locust
- ~2,000 seconds total compute time
- 1.11s average per request → ~0.9 RPS per pod
Configuration:
- 1 T4 GPU per service
- 1 audio feature extractor
- 1 video feature extractor
- 1 classifier
Comparison with Original Sequential Workflow
| Implementation | Avg Time (s) | Throughput (RPS) | Improvement |
|---|---|---|---|
| Sequential (initial) | ~15 | 0.066 | — |
| Parallel (no disk) | ~4.2 | 0.238 | 3.6× |
| Kafka-based (T4 per service) | ~1.1 | 0.9 | 13.6× overall |
5. Scaling to 500K Videos per Day
At 1.11 seconds per video, one GPU pod processes 77,700 videos/day (24h period)
To achieve the original 500,000 videos/day, we would need to horizontally scale by a factor of 7:
6. Conclusion
Through a series of architectural and performance-driven optimizations, we transformed a monolithic 15-second sequential pipeline into a high-performance distributed service capable of scaling to hundreds of thousands of videos daily.
Key Takeaways
- Eliminate I/O bottlenecks: In-memory streaming and avoiding disk writes yield immediate gains.
- Decouple workloads: Distributed architectures enable scalability and isolation of compute-heavy tasks.
- Batching: GPU efficiency scales with batch size.